前言
想给骰娘接 deepseek api,但是却在何时触发回复上犯愁。
先前见过关键词匹配的,概率触发回复然后一定时间内将所有发言均作为输入触发回复的,和通过指令前缀触发回复的,但是这些方式都不能达到希望的表现。
自己希望的表现到底是什么?经过思考,终于发现自己想要的是:
适用于全部群聊,所以触发频率不能太高
不能影响作为主业的跑团
像有独立的人格,被喊到的时候、或是被发言引起兴趣的时候才会生成回复
我要给千秋完整的一生
概率触发回复确实能让机器人像有自己的人格,但是适合用在白名单模式上,不适合全局开放使用,也容易影响跑团。
指令前缀触发显得一点都不酷。
要实现这些,最好是让骰娘自己判断需不需要回复。
可以考虑以下方式:
- 关键词匹配
通过设置与骰娘名字相关的关键词或短语,当群聊内容中包含这些关键词时生成回复。
太简陋了点,而且简单的关键词匹配容易在不应该回复的场合生成回复,影响跑团。
- 使用 deepseekapi 判断
专门写一份让 deepseek 判断发言是否与骰娘有关的 prompt,每次收到回复即调用。
但是钱包不同意。
- 文本分类
使用文本分类模型,分析用户发言的语义,判断是否与骰娘相关。
需要一定的数据量进行训练,而且需要考虑模型推理硬件性能要求与响应速度。
经过尝试,BERT 模型在我的 e3 小鸡上面运行效率不错,占用资源也不算多,故决定采用文本分类模型实现。
环境准备
1 | git clone https://github.com/google-research/bert.git |
原库的requirements.txt里面只写了一行tensorflow >= 1.11.0,这里给出我在本地(cpu 环境)测试时的环境。
也就在本地测试运行的时候会用到了,训练还得去租卡,而平台应该都会预装好大部分要用到的库罢,富哥当我没说
也许里面有些库是不必要的,懒得找了
下载预训练模型
同参考博客
准备数据集
留出法的训练数据集需要三个文件,classes.tsv、train.tsv、dev.tsv。
classes.tsv用于提供标签。
1 | unrelated |
train.tsv用于提供训练数据,每一行数据对应一个标签,数据后的数字说明此条数据对应classes.tsv中对应行数的标签
1 | 不是说七海很温柔的吗 0 |
dev.tsv用于提供评估数据,与train.tsv格式一样,一般来说 训练数据数 : 评估数据数 = 4 : 1。
经过从测试群聊收集数据和自己瞎编,也是终于凑够了需要的数据量。
在早期测试时,因为数据量过少,我甚至把一条数据换几种不同的称呼当作几条数据来用,像是把谢谢你,七海复制成谢谢你,千秋, 谢谢你,娜娜米等几份
后来经过一段时间的公测,收集到的数据也多了,终于能够将重复数据除去。
下图是带有重复数据的 800+条数据时和去重后剩下 500+条数据时的训练模型效果对比,显然后者的准确率高得多。
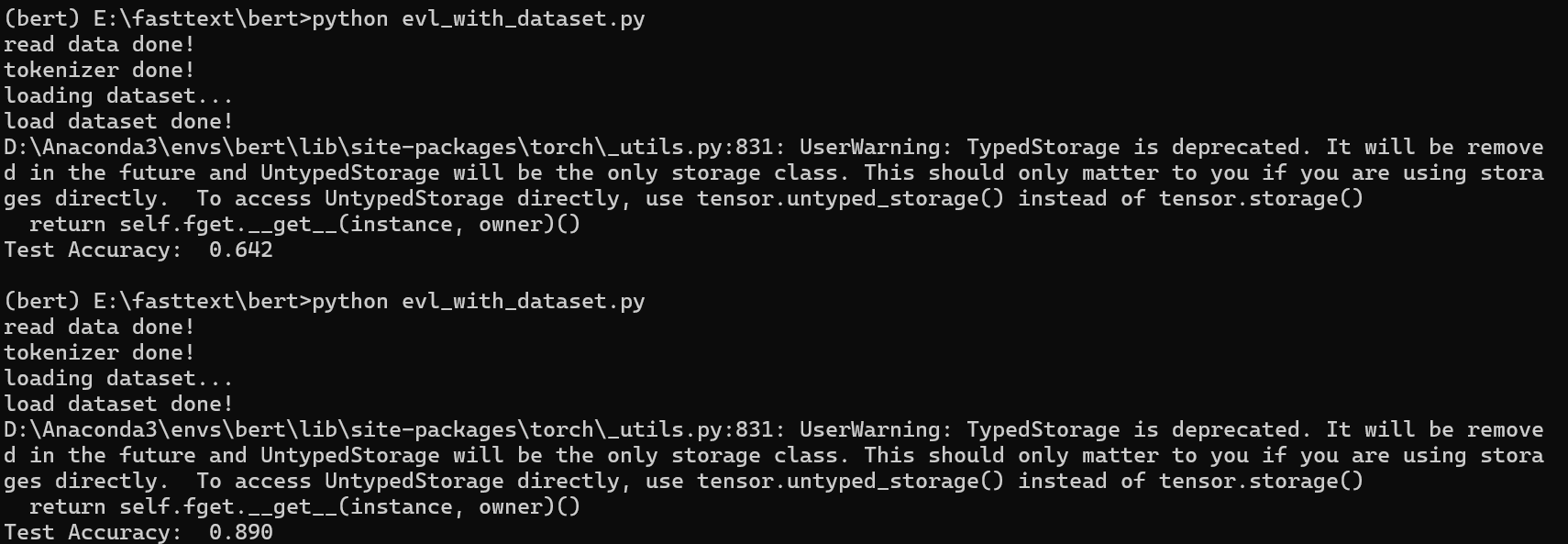
我训练时使用的完整数据集在这,可以做个参考。
训练
不是富哥建议租卡练,训练几分钟就能练上百轮,花不了几个钱。
训练代码相关库在这
这个训练代码的训练方式为留出法,数据集准备见上节,而库中除此之外还有交叉验证法和自助法的训练代码,如果有相关基础可以用这两种训练方法,貌似在数据量较少的时候也能有较好的效果,不过库中的服务端server.py并没有对这两种方法训练出来的模型做适配,需要改改。
开练

loss 和准确率基本上不动的时候就是差不多了,再练下去就过拟合了。
best.pt保存的是开发集准确率(Val Accuracy)最高的一轮,建议手动把epoch设为合适的轮数,或者手动停下程序,不然轮数太多不好说best.pt会不会保存到过拟合的结果。
推理模型
启用 http 客户端,交互式推理模型生成分类结果
服务默认开启于端口 15974,读取bert_checkpoint/best.pt模型。
目前仅支持以 post 方式调用,上报数据示例:
1 | { |
响应数据:
1 | { |
神奇妙妙工具
这里给出了几个 python 文件,在处理数据集的时候也许有用处。
dataset_clean.py
实现数据集去重,自动读取names列表作为称呼列表,读取文件后将不同称呼的相同发言删为一条。
dataset_make.py
读取插件的日志文件,生成数据集文件,可以快捷地将测试日志中的用户发言输入转变为数据集格式。
dev_get.py
读取训练数据集,随机抽取五分之一作为评估数据集。
后记
写好插件,开始测试之后发现效果其实还不错。
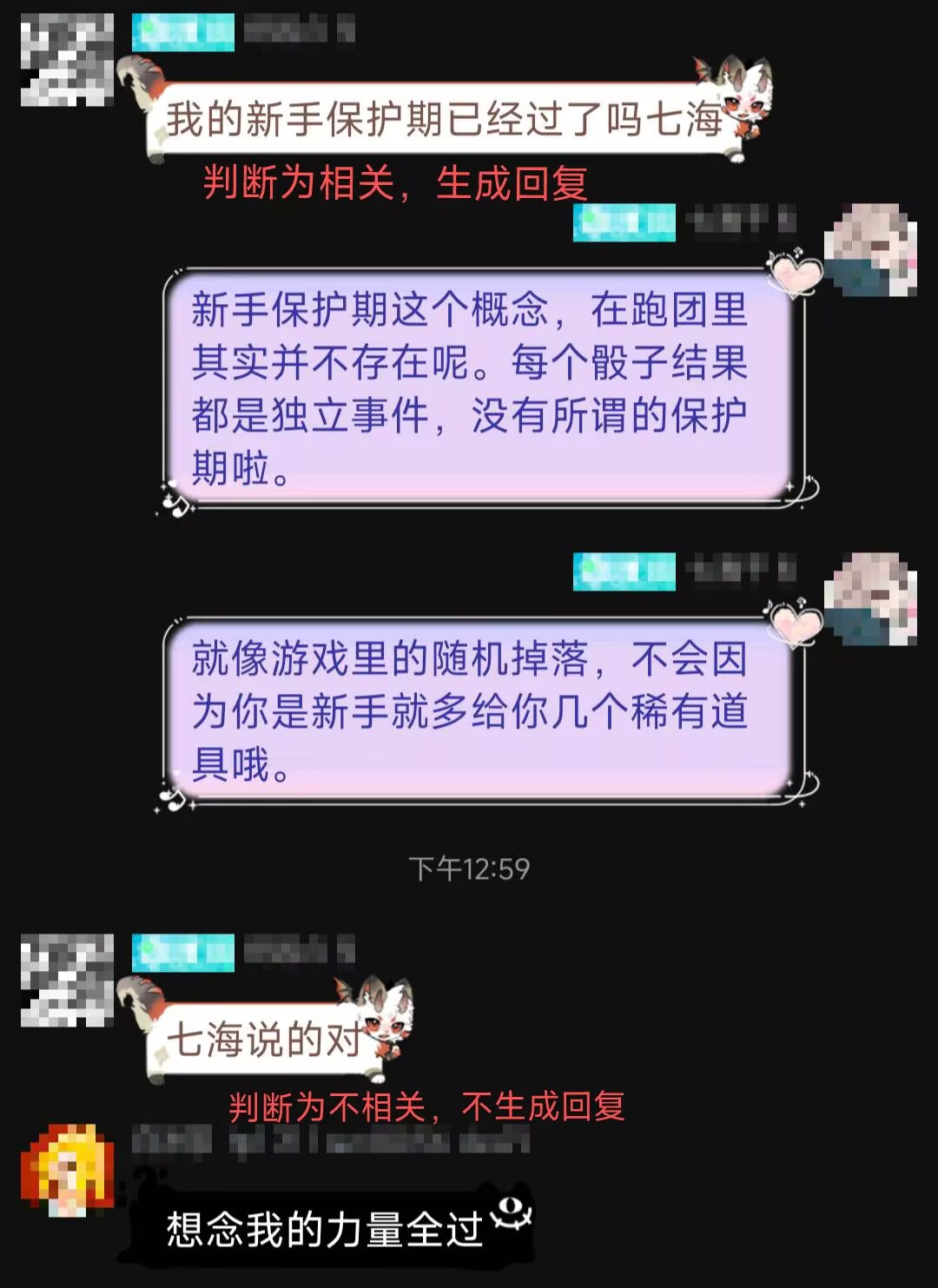
但是目前的训练数据集是侧重于用户发言中包含有对千秋的称呼时,是否要生成回复。
而数据集都是人工打标的,这也就说明所谓的”骰娘判断是否需要回复”,实质上是”骰娘判断这条发言在骰主心中是否要回复”
所以模型的效果好坏其实并没有标准,全看符不符合骰主预期。
另外用户的发言还有一部分可能连真人不好判断是否需要回复,不过都不算什么大问题,模型嘛,能达到预期表现就好。
本文代码参考此博客
- 本文标题:基于BERT的群聊消息分类模型训练
- 创建时间:2025-02-27 22:49:54
- 本文链接:2025/02/27/基于BERT的群聊消息分类模型训练/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!